こんにちは!バックエンドエンジニアの谷口(@ravineport)です。 本日はGoogle Cloud Platform(以下 GCP)のサービスの1つであるDataflowを使ってみたのでそのご紹介です。 Dataflowではストリームデータ処理とバッチデータ処理を行うことができるのですが、今回はストリームデータ処理の方をやってみました。
Dataflowとは
GCPのDataflowのドキュメントから引用しますと
Dataflow は、統合されたストリーム データ処理とバッチデータ処理を大規模に提供する Google Cloud サービスです。
ということだそうです。 処理自体はApache Beamを使って書きます。Apache Beamの実行環境の1つがDataflowと考えるといいかもしれません。
Apache Beam + Dataflowの組み合わせがとても強力で、大規模なストリーム処理をする際に考慮しなければならないところをよしなにサポートしてくれます。 そのよしな感を本記事で感じていただければ幸いです。一言で言ってしまうと「渡ってくるデータに対してどんな処理をするのかに集中することができる」かなと思います。 例えば処理を実行するためのワーカーの割り当てやスケーリング、GCPの各サービスとの連携、分散処理を意識せずに分散処理を書くことができる、などなどです。
今回作成するアプリケーション
ベタな例ではありますがワードカウントを作ってみようと思います。 ただしストリームデータ処理ということでパイプラインへの入力はCloud Pub/Subにします。また、単語のカウント結果はCloud SQLに出力するようにします。Pub/Subにpublishされる単語をDataflowでsubscribe & カウントして一定時間ごとにCloud SQLのword_countsテーブルに単語ごとの累計カウント数を記録していきます。
図にするとこんな感じです。

また、パイプラインの実装にはJavaを使います。
前準備
今回のアプリケーションを動かすにあたって必要なものを作成していきます。詳細な手順については公式ドキュメントをご参照ください。 また、すべて同一のプロジェクトでリージョンはすべてasia-northeast-1で作られているものとします。
Cloud Pub/Sub
word-countという名前のTopicを作成しておきます。Subscriptionは作成しないで大丈夫です。
トピックの作成と管理 | Cloud Pub/Sub ドキュメント | Google Cloud
Cloud SQL for PostgreSQL
PostgreSQLのインスタンスをプライベートIPで作り、その際設定したVPCネットワークをメモしておきます。 プライベート IP の使用方法の詳細 | Cloud SQL for PostgreSQL | Google Cloud
作成したインスタンスに接続して以下のようなtest_dbという名前のデータベースと以下のテーブルを作成しておきます。
CREATE TABLE word_counts ( word varchar(40), count integer, PRIMARY KEY(word) );
Cloud Storage
word-count-temp-locationという名前のバケットを作成しておきます。
Javaによるパイプラインの実装
突然ですが全コードを載せてみます。筆者はJavaに明るくないため至らない点はご容赦くださいmm
Main.java(折りたたんであります。この行をクリックすると展開されます)
package org.example; import org.apache.beam.runners.dataflow.options.DataflowPipelineOptions; import org.apache.beam.sdk.Pipeline; import org.apache.beam.sdk.io.gcp.pubsub.PubsubIO; import org.apache.beam.sdk.io.jdbc.JdbcIO; import org.apache.beam.sdk.options.Description; import org.apache.beam.sdk.options.PipelineOptionsFactory; import org.apache.beam.sdk.options.Validation; import org.apache.beam.sdk.transforms.Count; import org.apache.beam.sdk.transforms.windowing.AfterProcessingTime; import org.apache.beam.sdk.transforms.windowing.AfterWatermark; import org.apache.beam.sdk.transforms.windowing.FixedWindows; import org.apache.beam.sdk.transforms.windowing.Window; import org.apache.beam.sdk.values.KV; import org.joda.time.Duration; public class Main { public static void main(String[] args) { WordCountOptions options = PipelineOptionsFactory.fromArgs(args).withValidation().as(WordCountOptions.class); options.setJobName("word-count"); options.setStreaming(true); // 簡単のためユーザー名やパスワードはハードコーディングしているが、実際はSecret Managerなどを使って取得する JdbcWriter writer = new JdbcWriter("jdbc:postgresql://[Cloud SQLインスタンスのIPアドレス]/[データベース名]", "[ユーザー名]", "[パスワード]"); Pipeline pipeline = Pipeline.create(options); pipeline .apply("Pub/Subのトピックから単語を読み込み", PubsubIO.readStrings().fromTopic(options.getInputTopic()).withTimestampAttribute("ts")) .apply("FixedWindowsでウィンドウに分割", window(10)) .apply("単語ごとにカウント", Count.perElement()) .apply("Cloud SQLに単語ごとにUPSERT", writer.write()) ; pipeline.run(); } public interface WordCountOptions extends DataflowPipelineOptions { @Description("読み込み先のPub/Subのトピック名") @Validation.Required String getInputTopic(); void setInputTopic(String value); } /** * 指定した秒数のFixedWindowsを作成する * * @param windowSizeSec ウィンドウの秒数 * @return Window<String> */ public static Window<String> window(Integer windowSizeSec) { return Window.<String>into(FixedWindows.of(Duration.standardSeconds(windowSizeSec))) // 集計結果をいつemitするかの設定(Trigger) .triggering( // ウォーターマークがウィンドウの終端を過ぎたらemit AfterWatermark.pastEndOfWindow() .withLateFirings(AfterProcessingTime.pastFirstElementInPane()) ) .withAllowedLateness(Duration.millis(1000)) .discardingFiredPanes(); } /** * JdbcIOを使ってPostgresのword_countsテーブルに単語ごとのカウントを書き込むためのクラス */ static class JdbcWriter { private final JdbcIO.Write<KV<String, Long>> writer; JdbcWriter(String url, String user, String password) { JdbcIO.DataSourceConfiguration config = JdbcIO.DataSourceConfiguration.create( "org.postgresql.Driver", url ).withUsername(user).withPassword(password); this.writer = JdbcIO.<KV<String, Long>>write().withDataSourceConfiguration(config); } JdbcIO.Write<KV<String, Long>> write() { return writer.withStatement("INSERT INTO word_counts (word, count) VALUES (?, ?) " + "ON CONFLICT (word) " + "DO UPDATE SET count = word_counts.count + EXCLUDED.count") .withPreparedStatementSetter((wordToCount, statement) -> { statement.setString(1, wordToCount.getKey()); statement.setLong(2, wordToCount.getValue()); }); } } }
build.gradle(折りたたんであります。この行をクリックすると展開されます)
plugins {
id 'java'
}
group = 'org.example'
version = '1.0-SNAPSHOT'
java.toolchain {
languageVersion = JavaLanguageVersion.of(17)
}
repositories {
mavenCentral()
maven {
url = uri('https://packages.confluent.io/maven/')
}
maven {
url = uri('https://repo.maven.apache.org/maven2/')
}
}
def beamVersion = '2.49.0'
dependencies {
implementation 'org.apache.beam:beam-sdks-java-core:' + beamVersion
implementation 'org.apache.beam:beam-sdks-java-io-google-cloud-platform:' + beamVersion
implementation 'org.apache.beam:beam-runners-google-cloud-dataflow-java:' + beamVersion
implementation 'org.apache.beam:beam-sdks-java-io-jdbc:' + beamVersion
runtimeOnly "org.postgresql:postgresql:42.2.27"
testImplementation platform('org.junit:junit-bom:5.9.1')
testImplementation 'org.junit.jupiter:junit-jupiter'
}
test {
useJUnitPlatform()
}
task execute(type: JavaExec) {
mainClass = 'org.example.Main'
classpath = sourceSets.main.runtimeClasspath
systemProperties System.getProperties()
args System.getProperty("exec.args", "").split()
}
とりあえずデプロイ、実行してみる
コードの解説は一旦置いて、まずはDataflowにデプロイ、実行してみたいと思います。Gradleのtaskを使ってデプロイと実行を同時に行います。
$ gradle execute -Dexec.args="\
--project=[プロジェクト名] \
--region=asia-northeast1 \
--gcpTempLocation=gs://word-count-temp-location \
--inputTopic=projects/[プロジェクト名]/topics/word-count \
--network=[Cloud SQLのインスタンスが置いてあるネットワーク名] \
--runner=DataflowRunner"
パイプラインがデプロイできたかどうかはGCPのコンソールからも確認できます。無事デプロイできたらPub/Subにpublishしてみます。
$ gcloud pubsub topics publish word-count --message='cat'
うまくいけばword_countsテーブルにカウントされたデータが入っています。
test_db=> select * from word_counts; word | count ------+------- cat | 1 (1 row)
複数回実行したり、その他の単語をpublishすると、その分単語ごとのカウント数が増えていくはずです。
コード解説
パイプラインの構成
コードの
pipeline
.apply(...)
と続いているところがパイプラインの構成を表しています。後ほど個々の要素については見ていきますが、分散処理でよく見るMap/Reduce等はなく、ただ流れてくるデータに対してどのような処理をするのかを定義している感じが見て取れるかと思います。
コードにも表れているように以下の要素からできています。
- Pub/Subのトピックから単語を読み込み
- FixedWindowsでウィンドウに分割
- 単語ごとにカウント
- Cloud SQLに単語ごとにカウント数をUPSERT
では個々の要素について見ていきます。
Pub/Subのトピックから単語を読み込み
Apache Beam SDKが提供してくれているPubsubIOを使ってPub/Subの指定したトピックからメッセージを読み取っています。実際にはパイプライン作成時にSubscriptionを自動で作成してそこから読み取っています。Pub/Subのコンソールを確認するとSubscriptionが作成されているのがわかると思います。
この出力はPCollection<String>という型でPubSubのメッセージをStringで受けています。PCollectionはApache Beam上の概念でここでは流れてくるデータの塊と捉えてもらえばOKです。
詳細な説明は公式ドキュメントを参照ください。
また、PubsubIOを使うとメッセージ IDに基づいて自動で重複排除をしてくれるのがうれしいポイントです。重複排除はPubsubIOの中で抽象化してくれているので特に気にする必要はありません(参考)。
Pub/Subにもexactly-onceの設定がありますが、これを有効にする必要はありません。逆に有効にしてしまうとメッセージの制限のためにパイプラインのパフォーマンスが低下してしまうので注意が必要です。
FixedWindowsでウィンドウに分割
ウィンドウ
個々のデータのタイムスタンプがついておりこれをイベント時刻(Event Time)と呼びます。ウィンドウはこれに基づいてPCollectionを分割するものです(公式ドキュメント)。Pub/Subの場合はデフォルトではpublishされた時点のタイムスタンプがイベント時刻になります(参考)。
publishされた時点のタイムスタンプではないもの、例えばJSONの中の特定フィールドの値をイベント時刻にしたい場合の方法は後述します。
ウィンドウの定義部分を見てみます。
public static Window<String> window(Integer windowSizeSec) { return Window.<String>into(FixedWindows.of(Duration.standardSeconds(windowSizeSec))) // 集計結果をいつemitするかの設定(Trigger) .triggering( // ウォーターマークがウィンドウの終端を過ぎたらemit AfterWatermark.pastEndOfWindow() .withLateFirings(AfterProcessingTime.pastFirstElementInPane()) ) .withAllowedLateness(Duration.millis(1000)) .discardingFiredPanes(); }
ウィンドウにはいくつか種類があるのですが今回は固定ウィンドウにしました。FixedWindows.of... がそれです。今回windowSizeSecには10を渡しているので10秒の固定ウィンドウです。例えば[2023-09-05 10:00:10, 2023-09-05 10:00:20), [2023-09-05 10:00:20, 2023-09-05 10:00:30)のようなウィンドウになります。
これで無限に流れてくるデータをウィンドウにまとめることで有限のデータセットとして扱えるようになりました。
次にウィンドウにまとめられたデータセットをどのタイミングで後続処理に流すのかを考える必要があります。それを決めるのがトリガーです。.triggering(...)の部分が該当します。トリガーの条件について説明するためにはウォーターマークという概念を理解する必要があるのでまずはそちらを説明します。
ウォーターマーク
Apache Beamのドキュメントから引用すると、ウォーターマークとは
watermark, which is the system’s notion of when all data in a certain window can be expected to have arrived in the pipeline
とあります。またStreaming 102: The world beyond batchによると
Watermarks: A watermark is a notion of input completeness with respect to event times. A watermark with a value of time X makes the statement: “all input data with event times less than X have been observed.” As such, watermarks act as a metric of progress when observing an unbounded data source with no known end.
とあります(余談ですが、この Streaming 102: The world beyond batch はストリーム処理を扱う上で必要な考えを丁寧に解説してくれているのでおすすめです)。
ウォーターマークとは時刻であり、例えばウォーターマークが時刻 t であるとは時刻 t までのすべてのデータが到着したということを表します。 ただし注意しなければいけないのは、あくまで予測でありウォーターマーク以降の時刻のデータがあとから現れることはありえるということです。
例えば[2023-09-05 10:00:10, 2023-09-05 10:00:20)という固定ウィンドウがあった場合で、ウォーターマークが2023-09-05 10:00:20を経過したとき、このウィンドウにはすべてのデータが集まったとみなすことができます。
しかし、現実では2023-09-05 10:00:19のデータがその後やってくるかもしれません。この場合はそういったデータは遅延データとして扱われます。
Dataflowのコンソールでは各ステップごとに入力のウォーターマークを確認することができます。
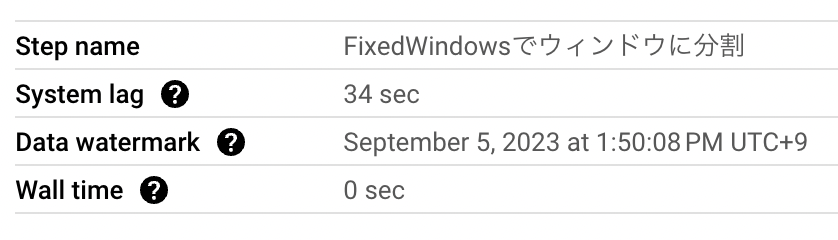
Data watermarkというのがそれで、このウィンドウのステップには2023-09-05 13:50:08までのすべてのデータが到着したと予想される、と読むことができます。ちなみにこのスクリーンショットを撮ったのは2023-09-05 13:50:40でした。
お察しの方もいらっしゃるかもしれませんが、イベント時刻で定義されたウィンドウには高精度なウォーターマークが必要です。ウォーターマークの精度が悪いと大量の遅延データが発生したり、データが破棄されてしまったりとパイプライン全体の処理に悪影響を及ぼしかねません。 Dataflow + Pub/Subを使うとこの問題をネイティブに解決してくれるようです(参考)。
トリガー
ウォーターマークについてはなんとなく理解していただけたでしょうか?(私はなかなかとっつけず理解に時間がかかりました…)
ウォーターマークがどんなものか捉えられると以下の部分も理解しやすいかなと思います。
.triggering(
// ウォーターマークがウィンドウの終端を過ぎたらemit
AfterWatermark.pastEndOfWindow()
.withLateFirings(AfterProcessingTime.pastFirstElementInPane())
)
.withAllowedLateness(Duration.millis(1000))
.discardingFiredPanes();
triggering(...)でどのタイミングでこのウィンドウの内容を発火させて次のステップに送るのかを定義しています。
AfterWatermark.pastEndOfWindow() でウォーターマークがウィンドウの終端が過ぎたら、という条件を表現できます。続くwithLateFiringsでは遅延データをどう扱うかを定義できます。
今回の場合はAfterProcessingTime.pastFirstElementInPane()としており、遅延データが1つでも入ってきたら発火、という意味になります。他にも一定数遅延データが溜まったら、といった条件を指定することもできます。
ここからも分かる通り、遅延データに関する条件によっては同じウィンドウが複数回発火することもあります。
withAllowedLateness(Duration.millis(1000))では遅延データをどれだけの時間許容するかを表しています。今回は1秒の遅延データを許可しています。それ以降のデータは破棄されてしまうので要件にあわせて遅延データの取り扱いを決める必要があります。
最後にdiscardingFiredPanes()では発火させたあとにそのウィンドウの内容を破棄する、ということを指定しています。同一のウィンドウでも遅延データの取り扱いによっては複数回発火する可能性があることを述べました。なので発火するたびにウィンドウの内容をどうするかを指定する必要があります。詳細は公式ドキュメントを参照ください。
まとめるとこのウィンドウは
- 1秒までの遅延データを許容する
- 発火タイミング
- ウォーターマークがウィンドウの終端を通過したとき
- 遅延データが1つ入ってきたとき
- 発火タイミング
- 発火後、ウィンドウの内容を破棄する
ということになります。
単語ごとにカウント
ウィンドウ処理が終わると次に単語ごとにカウントを行います。
この処理にはApache Beam SDKが提供しているCount.perElement()を使いました。これはPCollection<T>をPCollection<KV<T, Long>>に変換するメソッドです。Tというのは任意の型で、今回は単語をStringとして扱うのでTの型はStringです。KV<T, Long>はT型をkey、Longをvalueとするkey-valueを表す型です。カウントなのでvalueはLong型というわけですね。
ウィンドウごとに単語のカウントが終わると次が最後のCloud SQLのテーブルに書き込みに行く処理です。
Cloud SQLに単語ごとにカウント数をUPSERT
この処理に関するクラスを以下のように定義しています。
static class JdbcWriter { private final JdbcIO.Write<KV<String, Long>> writer; JdbcWriter(String url, String user, String password) { JdbcIO.DataSourceConfiguration config = JdbcIO.DataSourceConfiguration.create( "org.postgresql.Driver", url ).withUsername(user).withPassword(password); this.writer = JdbcIO.<KV<String, Long>>write().withDataSourceConfiguration(config); } JdbcIO.Write<KV<String, Long>> write() { return writer.withStatement("INSERT INTO word_counts (word, count) VALUES (?, ?) " + "ON CONFLICT (word) " + "DO UPDATE SET count = word_counts.count + EXCLUDED.count") .withPreparedStatementSetter((wordToCount, statement) -> { statement.setString(1, wordToCount.getKey()); statement.setLong(2, wordToCount.getValue()); }); } }
書き込みにあたってはApache Beam SDKが提供しているJdbcIOを使っています。
単語とそのカウント数のkey-valueであるKV<String, Long>を受け取ってUPSERTを行っています。
ここまでのまとめ
全体の流れの解説は以上です。Apache Beamのプログラミングモデル + Pub/Sub + Dataflowで流れてきたデータに対してどんな処理を行うかに集中して実装できる、そのよしな感を少しでも感じていただければ幸いです。
また、IOについてはApache Beamが提供するI/O Connectorを使うのが基本的によさそうです。
TIPS
今回の例だけでは紹介しきれなかったTIPSをつらつらと書いていきます。
Pub/Subからのデータに独自のイベント時刻をつける
今回の例ではPub/Subから送られてくるデータのイベント時刻は自動でつけてもらっていましたが、これを独自で設定したいケースがあります。例えばJSONデータを扱うとして、特定フィールドの値をイベント時刻としたい場合が考えられます。
これをPubsubIOの後続処理でJSONをパース、イベント時刻を特定フィールドの値で上書きということをしようとすると次のようなエラーが出るかもしれません。
Output timestamps must be no earlier than the timestamp of the current input
これは元のイベント時刻より古いイベント時刻を付与しようとしているためです。
ではどうするのかというと、publishのときに追加属性としてタイムスタンプをつけて、パイプライン側でその属性をイベント時刻として扱います。publish側は
gcloud pubsub topics publish word-count --message='cat' --attribute="ts=1693899972927"
のようにして
パイプライン側では
PubsubIO.readStrings().fromTopic(options.getInputTopic()).withTimestampAttribute("ts")
のようにします。
自動で作られたPub/SubのSubscriptionは消える可能性がある
今回の例ではTopicだけ指定してSubscriptionはDataflowに作ってもらいましたが、自動で作成されたSubscriptionは31日間アクティビティがないと自動で削除されてしまいます。
要件によってはSubscriptionは自前で作成して、パイプラインの実装ではそこから読み取る方がよいかもしれません。
ローカルで実行する
今回の例では以下のように実行してDataflow上で実行しました。
gradle execute -Dexec.args="\
--project=[プロジェクト名] \
--region=asia-northeast1 \
--gcpTempLocation=gs://word-count-temp-location \
--inputTopic=projects/[プロジェクト名]/topics/word-count \
--network=[Cloud SQLのインスタンスが置いてあるネットワーク名] \
--runner=DataflowRunner"
これをローカルでも実行することができます。
--runner=DataflowRunnerとしているところを--runner=Direct とすることでローカルでも実行可能です。
ただし、ローカルとDataflowでは実行時の挙動が異なることがあります。例えばこちらの記事で紹介されているようにPubsubIO と AfterWatermark Trigger の組み合わせがうまく機能しない等があります。
ローカルで実行して思ったような動作にならないときはDataflowで実行してみるとよいかもしれません。
水平スケーリング
水平スケーリングの設定は実行時のパラメータをいくつか足してあげるだけです。
--autoscalingAlgorithm=THROUGHPUT_BASED \ --maxNumWorkers=N
以前はStreaming Engineを使わないと一度デプロイしたジョブの最大数を増やすことはできませんでしたが、2023年8月15日のアップデートで停止しなくても増やすことができるようになりました。
GitHub Actionsを使ったデプロイ
まずパイプラインの更新についてですが、実行時のパラメータに--updateをつける必要があります。
また、更新の際にはJob Nameを参照します。今回の例だとコードの中にJob Nameをハードコーディングしているので実行時のパラメータに--updateをつければ更新できます。
GitHub Actionsを使ってデプロイしたい場合は、デプロイしたいパイプラインが既に実行中かどうかを判断する必要があります。その例を書いてみます。
jobs: # 色々前処理 - name: Check and set if dataflow job is running id: setStatus run: | status=`gcloud dataflow jobs list --region asia-northeast-1 --status=active | grep word-count | awk '{print $6}'` echo "STATUS=${status}" >> "$GITHUB_OUTPUT" - name: Create dataflow job if: ${{ steps.setStatus.outputs.status != 'Running' }} run: | gradle execute -Dexec.args="\ --project=[プロジェクト名] \ --region=asia-northeast1 \ --gcpTempLocation=gs://word-count-temp-location \ --inputTopic=projects/[プロジェクト名]/topics/word-count \ --network=[Cloud SQLのインスタンスが置いてあるネットワーク名] \ --runner=DataflowRunner" - name: Update dataflow job if: ${{ steps.setStatus.outputs.status == 'Running' }} run: | gradle execute -Dexec.args="\ --project=[プロジェクト名] \ --region=asia-northeast1 \ --gcpTempLocation=gs://word-count-temp-location \ --inputTopic=projects/[プロジェクト名]/topics/word-count \ --network=[Cloud SQLのインスタンスが置いてあるネットワーク名] \ --runner=DataflowRunner \ --update"
gcloudコマンドを使ってword-countジョブのステータスを取得してそれによって--updateをつけるかつけないかをわけています。
ただし、パイプラインの構成を変えすぎると--updateをつけても更新できない場合があるのでご注意ください。詳細は公式ドキュメントを参照ください。
参考文献
この記事を書くにあたって参考にさせていただいた記事を紹介します。
- Dataflowの「Apache Beamのプログラミングモデル」
- Apache Beamの公式ドキュメント「Basics of the Beam model」
- Dataflowのドキュメントでさくっと解説されている、もしくは触れられていない概念をより深く知るために参考にさせてもらいました。
- 実際のコードと合わせて知りたい場合はこちらも。
- 「Streaming 102: The world beyond batch」
- ストリーム処理とはなんぞを知るためにApache Beamで登場する概念が登場します。
- とっつきにくい概念(e.g. Watermark)がなぜいるのか、どういった概念なのかを理解するのに役立ちました。
- 日本語で要約もしてくれています:【要約】The world beyond batch: Streaming 102 - Qiita
- Dataflowが解決するストリーミング処理の課題と基盤構築で考慮すること
- ストリーム処理とはなんぞをいい感じにまとめてくれている記事です。
- Cloud Dataflow for Java 雑多なノウハウ集 - 実装編
- 詰まったときにドンピシャのことが書いてありとても助けていただきました。
おわりに
ワードカウントを例にDataflowでストリーム処理をやってみました。新しい概念に出会うこともできとても楽しかったです!実際に運用するのは少し先ですが、またなにか知見が得られたときには記事にしたいと思います。これからDataflowでストリーム処理をやってみたいという方の一助になれば幸いです。
エモーションテックでは顧客体験、従業員体験の改善をサポートし、世の中の体験を変えるプロダクトを開発しています。 この記事や他の記事を見て少しでも弊社に興味を持っていただけましたらカジュアル面談からでも是非お話させてください!