はじめに
こんにちは、バックエンドエンジニアのおおたわらです。
過去にもこのブログで紹介したことがありますが、弊社ではマイクロサービス(言語は Rust、Node.js、Python など)の実行基盤として Cloud Run を利用しています。 アプリケーションのエラーについては現在 Cloud Monitoring によるログベースの監視を行っていますが、同原因のエラーがまとめられずエラーの対応状況の管理が困難なため、Error Reporting の利用を検討しています。
Error Reporting はログに出力されたスタックトレースに基づいてエラーをグループ化し、発生回数の集計などを自動で行ってくれる便利なサービスです。 ところが、スタックトレースを解析できるのは一部の言語のみであり、例えば弊社で使っている Rust については対応していません。
こういった言語についても活用ができるのかを探るべく、Error Reporting へのエラーの報告の方法やグループ化の仕組みについて調べたので記事にしてみます。
エラーの報告
Error Reporting へのエラーの報告方法には、大きく以下の2つがあります。
- Error Reporting API による明示的な報告
- Cloud Logging に出力されたログのうちエラーのテキストパターン(スタックトレースなど)を Error Reportingに検出させる
API を使う方法の場合、アプリケーション側でエラー発生ごとに都度 API 呼び出しによる報告が必要です。
一方、Cloud Logging による方法であれば指定の形式でエラーログを出力しておけばよいため、実装時に意識することは少なく済むと思われます。また、Cloud Run や App Engine などのサービスであれば特に何も設定をしなくても Error Reporting によりエラーの検出が行われます。
今回は Cloud Logging による報告の詳細について紹介します。 ログの記録方法は以下の2つがあります。
- スタックトレースを記録する
- テキストメッセージを記録する
参考:ログでエラーをフォーマットする | Error Reporting | Google Cloud
スタックトレースを記録する
ログに指定の形式でスタックトレースを記録することで、Error Reporting がスタックトレースを自動で解析し類似とみなされたエラーをグループ化します。(グループ化の詳細なロジックについては後述します。)
この記事公開時点では以下の言語のスタックトレースのみが解析可能です。つまり Rust ではこの方法を使うことはできません。
例外スタック トレースのパーサーは、Go、Java™、.NET、Node.js、PHP、Python、Ruby を解析できます。
参考:Error Reporting の概要 | Google Cloud
スタックトレースは以下のいずれかの形式で記録します。
- 複数行の
textPayload message、stack_trace、exceptionフィールドを含むjsonPayloadmessage、stack_trace、exceptionフィールドを含まないがスタックトレースが含まれるjsonPayload
試しに Cloud Run 上で動く Node.js のアプリケーションから以下のようにログを出力してみます。
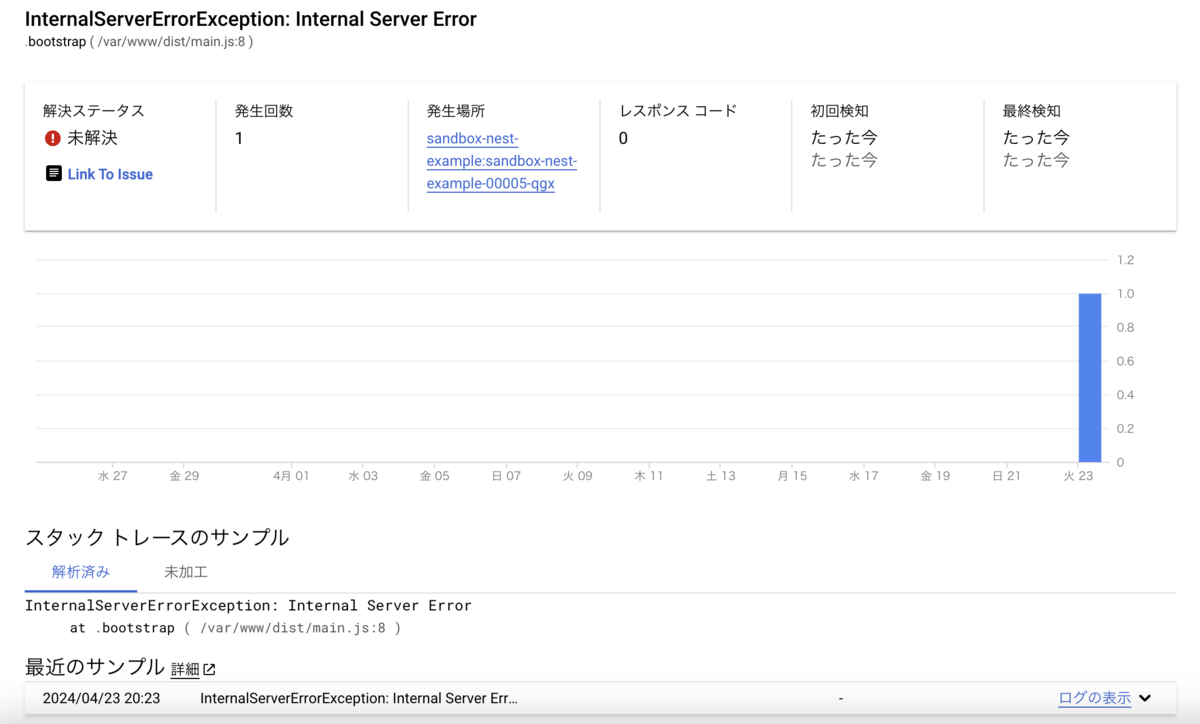
{ "jsonPayload": { "stack_trace": "InternalServerErrorException: Internal Server Error\n at bootstrap (/var/www/dist/main.js:8:47)" } }
以下のように検出されました。スタックトレースの情報によりエラーがグループ化された上で、エラー発生場所のソースコード位置も認識されています。また、「発生場所」として Cloud Run のサービス・リビジョン名が表示されています。
テキストメッセージを記録する方法
以下のように、jsonPayload に @type として Error Reporting のイベントであることの指定と、メッセージの指定をすることで報告が可能です。
詳細なロジックについては後述しますが、 message フィールドがエラーのグループ化に使われます。
"jsonPayload": { "@type": "type.googleapis.com/google.devtools.clouderrorreporting.v1beta1.ReportedErrorEvent", "message": "Text message" }
Cloud Run で動く Rust アプリケーションから上記のようなログを出力してみたところ、Error Reporting に報告できました🎉
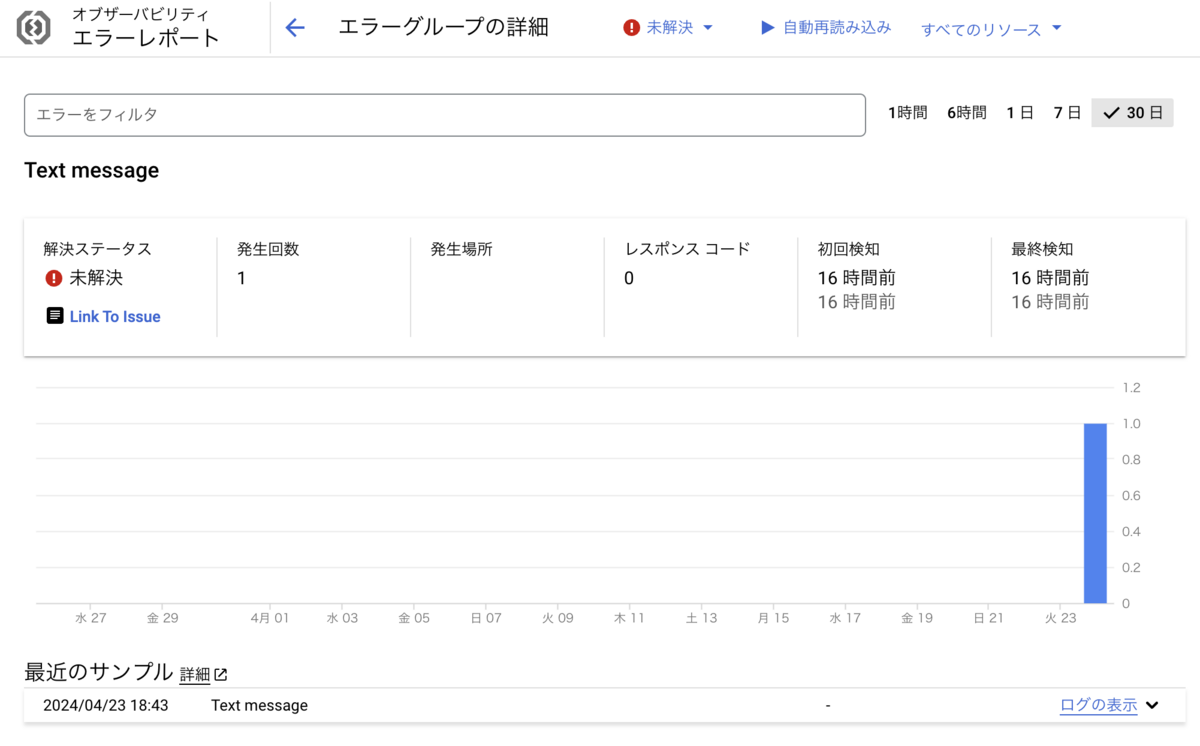
ですが、スタックトレースによる報告の結果と比べるとどの Cloud Run サービスで発生したのかなど、エラーに関する情報が少ないです。 なぜこうなるのかは明確な情報がないのですが、Error Reporting に自動で収集されたものではなくこちらからエラーだと認識させているので、自動で発生元の情報が取得されない可能性があります。
ログを ReportedErrorEvent の形式にフォーマットすることで情報を付与することができます。一部、エラーの調査時に役立ちそうなフィールドを紹介してみます。
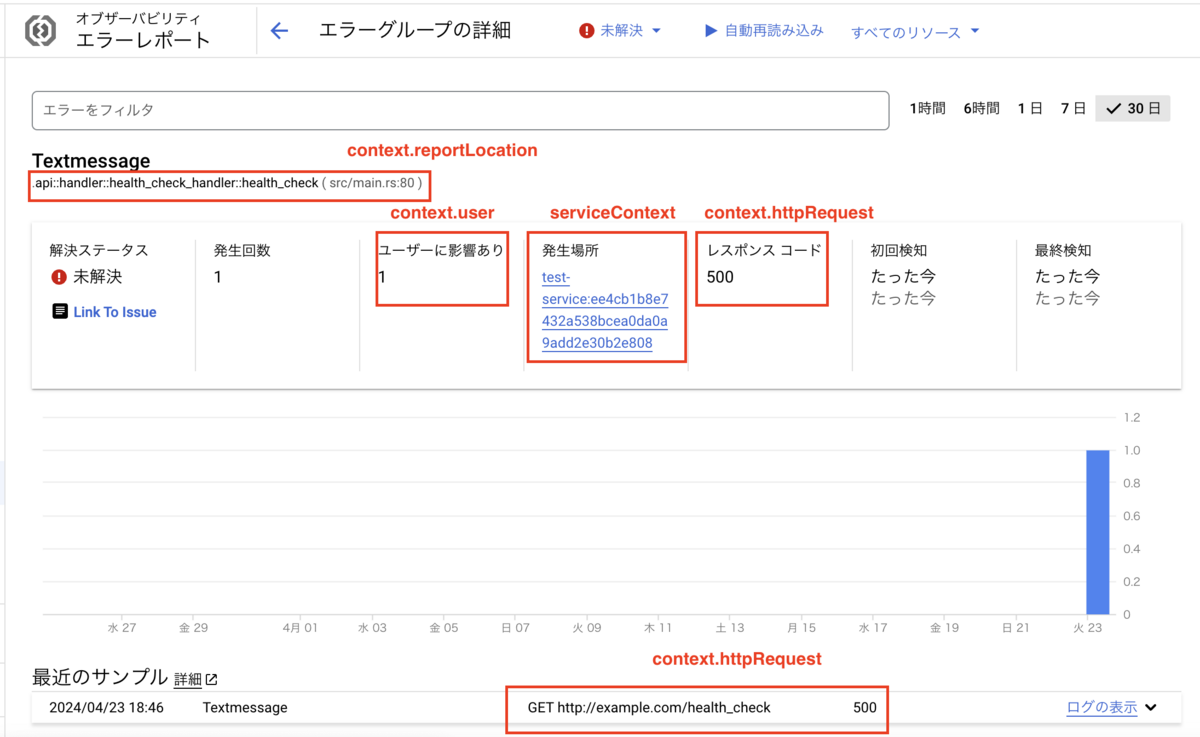
serviceContext:エラーが発生したサービスの情報。Error Reporting のコンソール画面では「発生場所」として表示される。message:エラーメッセージ。context.reportLocationの指定がない場合は、ヘッダー(例外のタイプとエラーメッセージ)とスタックトレースを含む必要がある(おそらく Error Reporting に発生箇所の情報を認識させる必要があるため)context:エラー発生のコンテキスト
試しに以下のように一部のフィールドを指定したログを出力してみます。
{ "jsonPayload": { "@type": "type.googleapis.com/google.devtools.clouderrorreporting.v1beta1.ReportedErrorEvent", "message": "Text message", "serviceContext": { "service": "test-service", "version": "ee4cb1b8e7432a538bcea0da0a9add2e30b2e808" }, "context": { "httpRequest": { "method": "GET", "url": "http://example.com/health_check", "responseStatusCode": 500 }, "user": "9f32f587135aa6774e78ed30fbaabcce3ec5528f", "reportLocation": { "filePath": "src/main.rs", "lineNumber": 80, "functionName": "api::handler::health_check_handler::health_check" } } } }
報告されたエラーをコンソールで確認すると、以下のようになりました。 設定した情報が表示されているのがわかります。
スタックトレースがないので呼び出し階層の情報は与えられませんが、ソースコード上の発生箇所については認識させることができます。
エラーのグループ化
次に、報告されたエラーがグループ化される方法を確認してみます。公式ドキュメントに記載があります。
Error Reporting の概要 | Google Cloud
以下の順でグループ化規則が適用されます。 基本は同じエラーのタイプ、発生箇所(ソースコード上のどの位置か、スタックトレースによって提供された呼び出し階層)が似ていれば同じグループになります。
| エラーの種類 | グループ化規則 |
|---|---|
| 環境内の一般的な問題に起因するエラー | 例外タイプによりグループ化 |
| スタックトレースがあるエラー | 例外タイプと上位 5 つのフレームによりグループ化 |
| スタックトレースはないが、メッセージがあるエラー | メッセージと(存在する場合は)関数名によりグループ化。最初の 3 つのリテラル トークンのみが考慮されます。 |
各エラーの種類について、詳細に確認してみます。
環境内の一般的な問題に起因するエラー
例えば以下のようなエラーです。
com.google.apphosting.runtime.HardDeadlineExceededError
こちらはアプリケーション内というよりは、クラウド環境で発生したエラーなどが該当するようです。例えば、運用する中で Cloud Run の HTTP 429: 使用可能なコンテナ インスタンスがない エラーがグループ化されているのを見たことがあります。
スタックトレースがあるエラー
例えば以下のようなエラーです。
runtime error: index out of range
package1.func1()
file1:20
package2.func2()
file2:33
弊社プロダクトでこの条件に当てはまるエラーを見てみると、確かに規則通りにグループ化されていそうでした。
例えば以下のような、メッセージは異なるが型が同じ Node.js のエラーは同じグループにまとめられていました(スタックトレースは同じです)。
NotFoundException: Cannot GET /api/hogeNotFoundException: Cannot GET /api/fuga
また、メッセージが同じだがスタックトレースが異なるエラーは別のグループとなっていました。
スタックトレースはないが、メッセージがあるエラー
例えば以下のようなエラーです。グループ化規則における「最初の3つのリテラルトークン」はこの例における、runtime、error、index です。
runtime error: index out of range
func1()
こちらについては、スタックトレースを解析できない言語の場合に活用できる方法かもしれないと考えて、深堀って挙動を確認してみました。 条件を変えた 2 つのエラーをログに出力して、どのようにグループ化されるか確認してみました。 推測も含まれますが、以下のような傾向が確認できます。 実際に使う上では、「最初の3つのリテラルトークンのみ考慮」に注意が必要そうです。エラーメッセージの出力の仕方によっては、原因の違うエラーが同じグループとして扱われてしまいそうです。
メッセージの組み合わせを変えてみる
関数名は同じ値 api::handler::health_check_handler::health_check としています。
| パターン | エラー1 | エラー2 | 結果 |
|---|---|---|---|
| 同一メッセージ | message1 | message1 | 同じグループ |
| 類似メッセージ | message1 | message1 | 同じグループ |
| 最初の 3 単語だけ同じメッセージ | Unexpected error occurred in bigquery | Unexpected error occurred in sqlx | 同じグループ |
| 最初の3単語内でID(ULID)だけ違うメッセージ | error id:01HW2N1BJV1J64ZSMQYSBK4J6B | error id:01HW2N0FKCEBBTH92SJH939R71 | 同じグループ |
| 大幅に異なるメッセージ | message1 | あああああ | 別グループ |
関数名を変えてみる
メッセージは同じ message1 にして関数名だけ変えてみての検証もしてみました。
| パターン | エラー1 | エラー2 | 結果 |
|---|---|---|---|
| 同一関数名 | api::handler::health_check_handler::health_check | api::handler::health_check_handler::health_check | 同じグループ |
| 類似関数名 | api::handler::health_check_handler::health_check | api::handler::health_check_handler::health_check2 | 別グループ |
Rust のエラー管理に使用できそうか
まだ悩み中ではあるのですが、以下のような方法でうまく Rust のエラーを報告できないか模索中です。
- スタックトレースを他の言語に近づける
- スタックトレースを出力せず、メッセージのみを報告する
- メッセージは狙った通りグループ化されるような指定をする
- 発生場所の情報は ReportedErrorEvent 形式により提供する
おわりに
Error Reporting への報告の仕方や、グループ化の挙動について調べてみました。同じように気になった方への参考となれば幸いです。
そして、Error Reporting により Rust のスタックトレースも解析できるようになることを祈っています。
エモーションテックでは顧客体験、従業員体験の改善をサポートし、世の中の体験を変えるプロダクトを開発しています。もし記事を通じて興味を持っていただけましたら、ぜひ採用ページからご応募をお願いいたします。