こんにちは、Emotion TechでSREチームに属している菅原です。
Pythonで実装されたデータ処理のテストを書く際に、まとまったテストデータが必要ということはあるかと思います。 今まではテスト用のCSVファイルを用意する or 適当な値を入れたPandasのデータフレームを用意する、で対応していました。 今回は、簡単にテストデータを用意する手段として、panderaの機能が使えないか試してみました。
panderaとは
panderaは、データフレームでデータバリデーションを実行して、データ処理パイプラインをより読みやすくロバストにするためのライブラリです。
公式ドキュメントの例をみてみましょう。
import pandas as pd import pandera as pa # data to validate df = pd.DataFrame({ "column1": [1, 4, 0, 10, 9], "column2": [-1.3, -1.4, -2.9, -10.1, -20.4], "column3": ["value_1", "value_2", "value_3", "value_2", "value_1"] }) # define schema schema = pa.DataFrameSchema({ "column1": pa.Column(int, checks=pa.Check.le(10)), "column2": pa.Column(float, checks=pa.Check.lt(-1.2)), "column3": pa.Column(str, checks=[ pa.Check.str_startswith("value_"), # define custom checks as functions that take a series as input and # outputs a boolean or boolean Series pa.Check(lambda s: s.str.split("_", expand=True).shape[1] == 2) ]), }) validated_df = schema(df) print(validated_df) # column1 column2 column3 # 0 1 -1.3 value_1 # 1 4 -1.4 value_2 # 2 0 -2.9 value_3 # 3 10 -10.1 value_2 # 4 9 -20.4 value_1
上記のようにデータバリデーションを行なうことができます。 また、DataFrameSchemaではなく、SchemaModelを使って以下のように書くこともできます。(こちらも公式ドキュメントより参照)
import pandera as pa from pandera.typing import Series class Schema(pa.SchemaModel): column1: Series[int] = pa.Field(le=10) column2: Series[float] = pa.Field(lt=-1.2) column3: Series[str] = pa.Field(str_startswith="value_") @pa.check("column3") def column_3_check(cls, series: Series[str]) -> Series[bool]: """ Check that values have two elements after being split with '_' """ return series.str.split("_", expand=True).shape[1] == 2 Schema.validate(df)
実際に色々生成してみた
SchemaModelを用いて色々な型のカラムを持つSchemaを定義し、データ生成を試してみました。 exampleメソッドを使うことで各カラムで指定した条件のデータを生成できます。引数のsizeで生成するデータ数を指定できます。
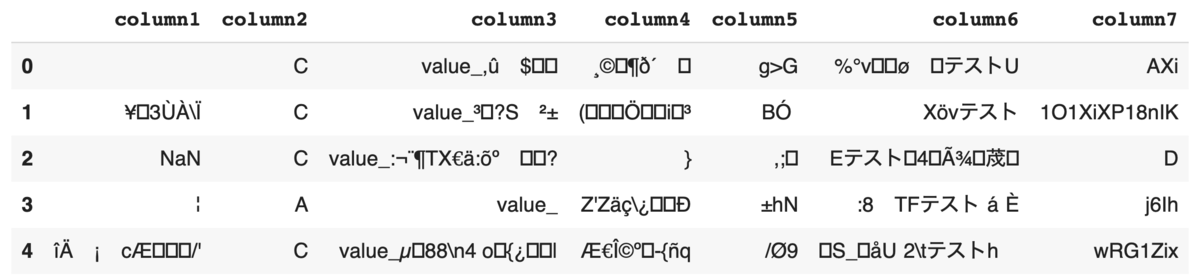
String
import pandera as pa from pandera.typing import Series class StringSchema(pa.SchemaModel): column1: Series[str] = pa.Field(nullable=True) column2: Series[str] = pa.Field( nullable=False, isin=("A", "B", "C")) column3: Series[str] = pa.Field( nullable=False, str_startswith="value_") column4: Series[str] = pa.Field( nullable=False, str_length={"min_value": 1, "max_value": 10}) column5: Series[str] = pa.Field( nullable=False, str_length={"min_value": 3, "max_value": 3}) column6: Series[str] = pa.Field( nullable=False, str_contains="テスト") column7: Series[str] = pa.Field( nullable=False, str_matches=r"[a-zA-Z0-9_]+") StringSchema.example(size=5)
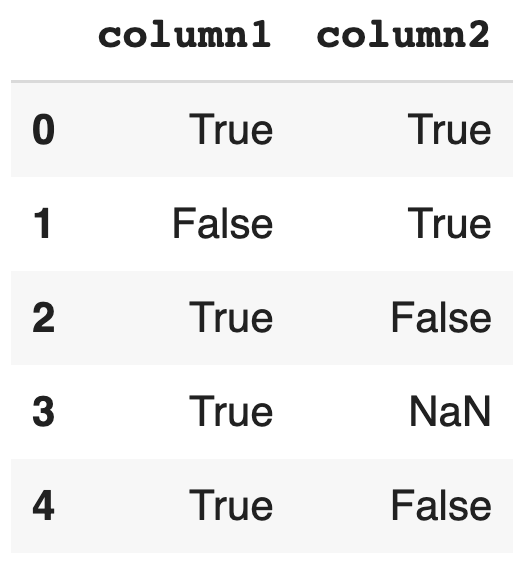
Boolean
import pandera as pa from pandera.typing import Series class BooleanSchema(pa.SchemaModel): column1: Series[bool] = pa.Field(nullable=False) column2: Series[bool] = pa.Field(nullable=True) BooleanSchema.example(size=5)
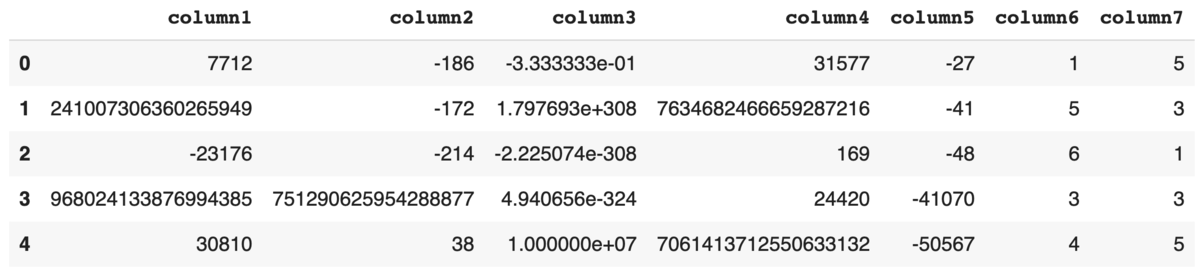
Number
import pandera as pa from pandera.typing import Series class NumberSchema(pa.SchemaModel): column1: Series[int] = pa.Field(nullable=False) column2: Series[int] = pa.Field(nullable=False, unique=True) column3: Series[float] = pa.Field(nullable=False) column4: Series[int] = pa.Field(nullable=False, ge=0) column5: Series[int] = pa.Field(nullable=False, le=0) column6: Series[int] = pa.Field( nullable=False, in_range={"min_value": 0, "max_value": 10}) column7: Series[int] = pa.Field(nullable=False, isin=(1, 3, 5)) NumberSchema.example(size=5)
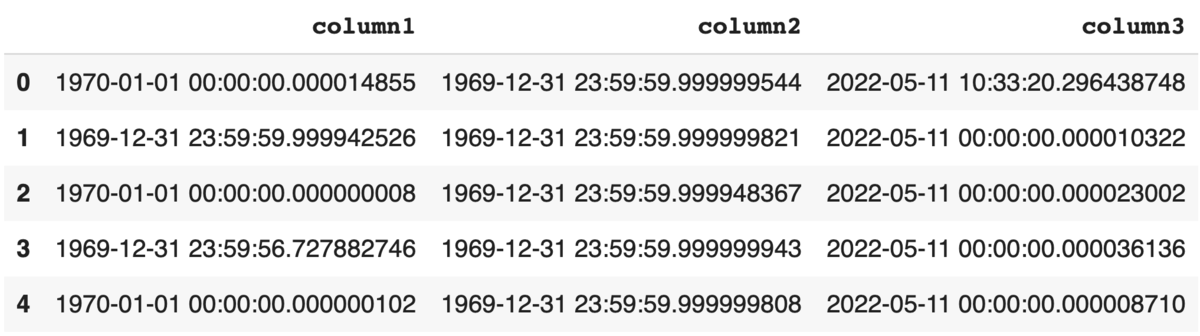
Timestamp
import pandas as pd import pandera as pa from pandera.typing import Series class TimestampSchema(pa.SchemaModel): column1: Series[pa.DateTime] = pa.Field(nullable=False) # alias of pandera.dtypes.Timestamp column2: Series[pa.Timestamp] = pa.Field(nullable=False) column3: Series[pa.Timestamp] = pa.Field(nullable=False, in_range={ "min_value": pd.to_datetime("2022-05-11T00:00:00"), "max_value": pd.to_datetime("2022-05-12T00:00:00"), }) TimestampSchema.example(size=5)
所感
バリデーションのために使うSchemaを定義しておくだけで、テストに使うためのデータ生成を簡単にできるのは良いなと思いました。ただ、データジョイン系のテストに使えるデータの生成はできないため、そこについては自前でどうにかしないといけなさそうです。
今回触ってみてその他気になった点としては以下になります。
- 生成される文字列について
- 複雑なバリデーション条件のカラムがあるとUserWarningが出てしまう
- 不具合に出くわした
生成される文字列について
文字化けしているような文字列が生成されるのでなんか不安になります。ただ、テストデータとしてはこういうデータの方が意味があるのかもしれません。
複雑なバリデーション条件のカラムがあるとUserWarningが出てしまう
以下のようなバリデーション条件のカラムを持つSchemaを定義した場合、データ生成時にUserWarningが発生します。
import pandera as pa from pandera.typing import Series class Schema(pa.SchemaModel): column1: Series[str] = pa.Field(str_startswith="value_") @pa.check("column1") def column_1_check(cls, series: Series[str]) -> Series[bool]: return series.str.split("_", expand=True).shape[1] == 2 Schema.example(df)
/usr/local/lib/python3.7/dist-packages/pandera/strategies.py:996: UserWarning: Column check doesn't have a defined strategy. Falling back to filtering drawn values based on the check definition. This can considerably slow down data-generation.
f"{warning_type} check doesn't have a defined strategy. "
パフォーマンス的にも悪いということなのでどうにか解決したかったのですが、解決まで至りませんでした。
不具合に出くわした
以下のようにunique条件を持つカラムと、ge(指定した値以上)とle(指定した値以下)の条件を持つカラムを持つSchemaを定義した場合に、データ生成を実行するとエラーが発生してしまいました。
import pandera as pa from pandera.typing import Series class RaiseUnsatisfiableSchema(pa.SchemaModel): column1: Series[int] = pa.Field(nullable=False, unique=True) column2: Series[int] = pa.Field( nullable=False, ge=0, le=10) RaiseUnsatisfiableSchema.example(size=5)
Unsatisfiable: Unable to satisfy assumptions of example_generating_inner_function
上記のSchema定義の場合、それぞれのカラムは独立しているため、上記エラーが発生しない認識なのですが、期待通りの動作をしてくれませんでした。 こちらも再現性を確認しただけに留まり、原因の特定には至りませんでした。 わかったこととしては、geとleを使いたい場合、in_rangeで代替することで期待通りの動作をしてくれていそうということです。 時間があれば、Issueを書いてみようと思います。
import pandera as pa from pandera.typing import Series class NotRaiseUnsatisfiableSchema(pa.SchemaModel): column1: Series[int] = pa.Field(nullable=False, unique=True) column2: Series[int] = pa.Field( nullable=False, in_range={"min_value": 0, "max_value": 10}) NotRaiseUnsatisfiableSchema.example(size=5)
最後に
いかがでしたでしょうか。個人的にはタイミングがあればバリデーション機能とともに使っていきたいなと考えています。ただ、先ほど記述した気になった点に関しては、もう少し深堀した方がよさそうなので、時間あるときに調査してみるつもりです。また、不具合の方は必要がありそうならIssueを書いてみようと思います。
現在、Emotion Techではエンジニアメンバーを募集中です。この記事や他の記事を見て弊社に興味をもっていただけましたら、ご応募お待ちしております。