こんにちは、エモーションテックでSREチームに所属しているsugawaraです。 以前panderaについての記事を書かせていただいたのですが、今回もpanderaについて書いてみます。
この記事は エモーションテック Advent Calendar 2022 の 15 日目の記事です。
はじめに
データフレームを扱う際、データのバリデーションを実施したいことがあると思います。panderaではそのような機能が提供されているのですが、どういうバリデーションができるのか具体的に見ていきます。
サンプルケース①
以下のようなデータフレームがあるとします。
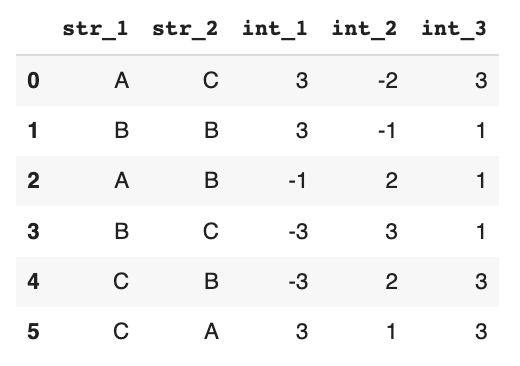
上記のデータフレームに対して、以下のようなバリデーションを実施したいとします。
- カラム名のprefixが「str」であるカラムについて
- 「A」「B」「C」いずれかの値を取り、各値を取る行が一つ以上存在する
- Nullは許容しない
- カラム名のprefixが「int」であるカラムについて
- 以下-3 ~ 3範囲のint型の値を取る
- 0より大きい値を取る行が一つ以上存在する
- 0より小さい値を取る行が一つ以上存在する
- Nullは許容しない
上記を実現するのが以下コードになります。
import pandera as pa schema = pa.DataFrameSchema({ "str.+": pa.Column( str, checks=[ pa.Check(lambda series: series.isin(["A", "B", "C"]), name="check_str_col_1"), pa.Check(lambda series: (series == "A").sum() > 0, name="check_str_col_2"), pa.Check(lambda series: (series == "B").sum() > 0, name="check_str_col_3"), pa.Check(lambda series: (series == "C").sum() > 0, name="check_str_col_4"), ], nullable=False, regex=True, ), "int.+": pa.Column( int, checks=[ pa.Check(lambda series: (-3 <= series) & (series <= 3), name="check_int_col_1"), pa.Check(lambda series: (series > 0).sum() > 0, name="check_int_col_2"), pa.Check(lambda series: (series < 0).sum() > 0, name="check_int_col_3"), ], nullable=False, regex=True, ), }) schema.validate(df)
実行結果はこちら。
SchemaError: <Schema Column(name=int_3, type=DataType(int64))> failed series or dataframe validator 2: <Check check_int_col_3>
エラーメッセージから「int_3」カラムのデータが「check_int_col_3」のチェックで失敗していることがわかります。入力のデータフレームを確認すると、「int_3」カラムのデータは全て正の値なので、バリデーションは期待した通りの結果となっています。
サンプルケース②
先ほどと同じデータフレームがあるとします。
上記のデータフレームに対して、以下のようなバリデーションを実施したいとします。
- カラム名が「str_1」であるカラムについて
- 「A」「B」「C」いずれかの値を取る
- Nullは許容しない
- カラム名のprefixが「int」であるカラムについて
- 以下-3 ~ 3範囲のint型の値を取る
- 「str_1」カラムが取りうる値ごとに0より大きい値を取る行が一つ以上存在する
- 「str_1」カラムが取りうる値ごとに0より小さい値を取る行が一つ以上存在する
- Nullは許容しない
上記を実現するのが以下コードになります。 今回groupbyを用いているのですがその際の注意点として、groupbyで指定しているカラムはDataFrameSchemaで定義してある必要があります。
import pandera as pa schema = pa.DataFrameSchema({ "str_1": pa.Column( str, checks=[pa.Check(lambda series: series.isin(["A", "B", "C"]), name="check_str_col_1")], nullable=False, ), "int.+": pa.Column( int, checks=[ pa.Check(lambda series: (-3 <= series) & (series <= 3), name="check_int_col_1"), pa.Check(lambda d: (d["A"] > 0).sum() > 0, name="check_int_col_2_1", groupby="str_1"), pa.Check(lambda d: (d["B"] > 0).sum() > 0, name="check_int_col_2_2", groupby="str_1"), pa.Check(lambda d: (d["C"] > 0).sum() > 0, name="check_int_col_2_3", groupby="str_1"), pa.Check(lambda d: (d["A"] < 0).sum() > 0, name="check_int_col_3_1", groupby="str_1"), pa.Check(lambda d: (d["B"] < 0).sum() > 0, name="check_int_col_3_2", groupby="str_1"), pa.Check(lambda d: (d["C"] < 0).sum() > 0, name="check_int_col_3_3", groupby="str_1"), ], nullable=False, regex=True, ), }) schema.validate(df)
もう少しスマートな書き方ができないか試行錯誤してみたのですが諦めました。 実行結果はこちら。
SchemaError: <Schema Column(name=int_2, type=DataType(int64))> failed series or dataframe validator 6: <Check check_int_col_3_3>
エラーメッセージから「int_2」カラムのデータが「check_int_col_3_3」のチェックで失敗していることがわかります。入力のデータフレームを確認すると、「str_1」カラムが「C」のデータは「int_2」カラムの値がどちらも正の値なので、バリデーションは期待した通りの結果となっています。
まとめ
いかがでしたでしょうか。 個人的には、groupbyを使えば複雑な条件のバリデーションを実現できるのはなかなか良いなと思いました。
We're Hiring!
エモーションテックでは顧客体験、従業員体験の改善をサポートし、世の中の体験を変えるプロダクトを開発しています。プロダクトに興味のある方、ぜひ採用ページからご応募をお願いいたします。