はじめに
こんにちは、株式会社Emotion Tech プロダクト開発部のおかざきです。今回は弊社サービスの品質向上を目指しNewRelic Oneをトライアルしたのでご紹介します。試して良いと感じた機能はいくつかありますが、そのうちの一つについて述べます。
※この記事は New Relic Advent Calendar 2021の11日目および Emotion Tech Advent Calendar 2021 12日目の記事になります。
やってみたこと
弊社のシステムはこちらの記事でご紹介している通りAWS上に構築されていますが、以下を実現するために、AWSの機能のみを用いる場合とNewRelicを用いる場合の手順を比較してみます。
- Ruby on Rails(以下、Rails)の操作ログを分析し、レスポンスタイムの値が一定値以上だった顧客ユーザについて所属企業と対象のエンドポイントを集計する
- アドホックに傾向を集計するためSQLに近い感覚で行えるようにする
Railsアプリケーションは複数の異なるサービスとして稼働するものが存在する
アプリケーションログはJSON形式で出力される。各レコードに顧客企業IDが出力される ログのイメージは以下の通り
{
"container": "app1",
"audit": {
"date": "2021/12/11 00:00:00 UTC",
"method": "GET",
"endpoint": "/hogehoge",
"status_code": 200,
"params": null,
"total_response_time": 0.196067348,
"user_id": "xxxxxxxxxxx",
"company_id": "yyyyyyyyyyy"
}
}
- 既存のS3に蓄積されたログを分析することを想定する
- ログのフィールドはアプリケーションのログ要件の変化に伴い変更される可能性がある
AWS, NewRelic共通で必要な手順
AWSの場合の手順
SQLベースで分析できるようにAthenaを利用することにします。 構成イメージは以下の通りです。
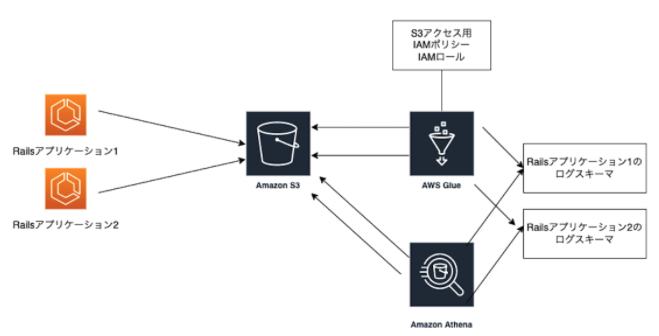
RailsログをAthenaで読み込ませるためのスキーマを定義します。この際AWS Glueを利用します。
GlueにてS3にアクセスするため、IAMポリシーとIAMロールを定義して、割り当てる ドキュメント
Athenaでクエリを書くときに、スキーマを指定する
ログのフォーマットが変わったら、スキーマを更新する
NewRelicの場合の手順
以下のNew Relicの記事で紹介されている手順を実施します。
Amazon S3に保存したログをNew Relicに取り込む
構成イメージは以下の通りです。
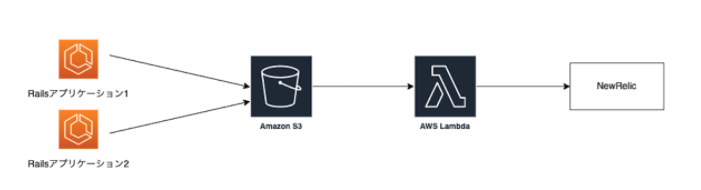
1.Amazon S3ログ転送のためのAWS Lambda関数をデプロイする
このLambdaは自前で書く必要がありません。「Serverless Application Repository」に登録されており、AWSコンソールでボタンをいくつかクリックするのと、ライセンスキーやログフォーマット等のパラメータを入力するだけでデプロイが可能です。
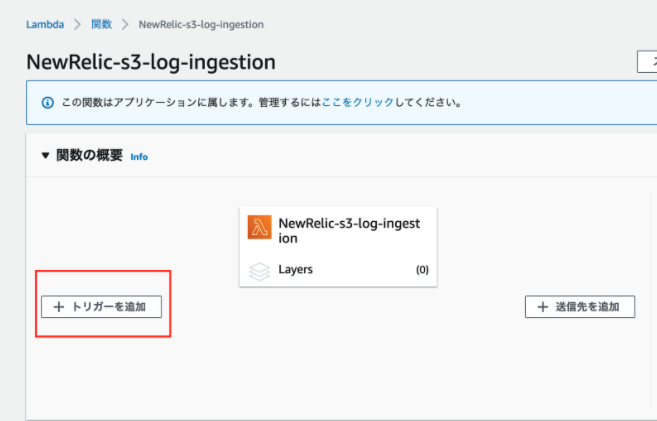
2.Lambda関数の発火トリガーを追加する
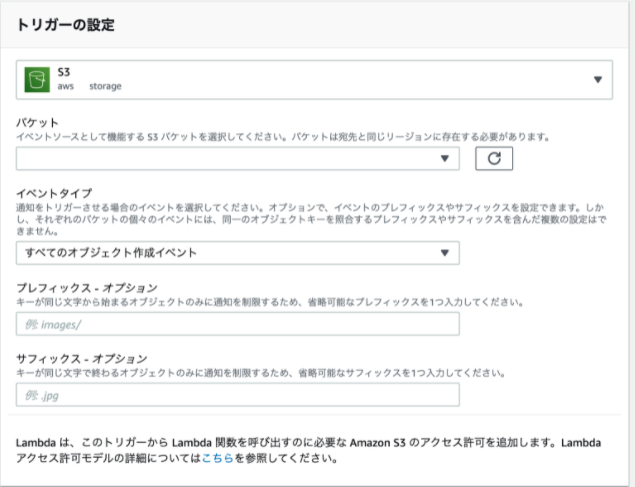
デプロイしたLambdaの画面より、ログを保存しているS3バケットとどのプレフィックス/サフィックスのついたログが更新されたらLambdaを発火するかを指定します。
以上で設定は完了です。ログがNewRelicに転送されるまで暫く待ちます。
ログが転送されたら以下のような形でクエリすることができます。
SELECT count(*) FROM Log FACET audit_company_id, audit_endpoint where audit_total_response_time > '10'
なお、NewRelicの場合は以下の特徴もあります。
- アプリケーションが複数あっても、ログがJSON形式である限り特に追加の設定は不要
- ログのフィールドに増減があっても、自動でキーを認識してくれるので特に対処不要
感想
AWSの場合はAthenaで読み込み可能なスキーマを作成する必要があります。AWS Glueのようなスキーマ認識のための仕組みは用意されていますが、習熟が必要になります。 また、アプリケーションの種類が増えたり、ログのフィールドが変更になると都度スキーマに手を加える必要があります。 これに対して、NewRelic Logsでは、ログがJSON形式で出力されていれさえすれば、自動でJSONのキーを使ってクエリを記述することができます。
一般的にアプリケーションのログをただ保存するだけならそこまで手間は掛かりませんが、 うまくログを活用するとなると分析のために地道な設定作業や更新・管理作業が必要で、辛さを感じると思います。 その点NewRelicを利用するとログの構造を自動で認識してくれるため、分析するまでの工程を減らすことができ、工数も心理的な負担も軽くなると感じました。
また、この記事ではアプリケーションの改修をせずに既存のS3に蓄積されたログを分析することを想定していますが、 こちらのNewRelicの記事にもある通り、ログライブラリから直接New Relic Logsに転送するエージェントレス送信が利用できるようです。
まとめ
ここではログ分析に絞って一つ紹介しました。 NewRelicを使って思ったこととして、システムのObservalibityを確保するには各種メトリクスの取得を気軽にできることも重要と考えます。一つ一つのメトリクスの取得の設定工数や管理工数が軽くないとメトリクスを取得する気が起きなくなってしまうので、そのような負担を軽減してくれる点は良いと考えます。
料金面でも、基本的にユーザ単位での課金(ログ転送ありの場合は転送量に応じた料金もあり)という形でわかりやすく、開発環境やステージング環境にも財務面に気を使うことなく導入できる点はメリットと思います。また、新機能が導入された場合も基本料金のまま利用できるので、気軽に試せそうと感じました。 例えばホスト単位課金では「経費削減のため商用環境は入れるけど開発環境には入れたくない」というような思考に陥りがちで、開発段階で性能傾向を掴めなくなるといったことにもなりえそうなので、課金体系のわかりやすさも良い点と考えます。
最後に
NewRelicをこれから活用していきたいと思いますが、システムを使うユーザの体験をより詳細に把握し、システムの品質向上に貢献していければと思います。 Emotion Techでは顧客体験、従業員体験の改善をサポートし、世の中の体験を変えるプロダクトを開発しています。この記事や他の記事を見て少しでも弊社に興味をもっていただけましたら、カジュアル面談も行っていますのでご応募お待ちしております。