はじめに
こんにちは、SREのおかざき(@tomoy_715)です。本記事ではSREチームとして今年やってきたことを振り返ってみます。
この記事はエモーションテック Advent Calendar 2024の16日目の記事です。
SREチームの紹介
簡単にSREチームの位置付けについてご紹介します。 SREチームは複数のプロダクトの開発チームを横断的に支援します。
開発初期から信頼性と開発生産性を意識し、開発メンバーが機能開発や改善にスムーズに取り組める環境を整備します。 また、開発メンバーが信頼性向上や顧客に届ける新たな価値を考える上で「試したい」と思ったことをすぐ行動に移せる環境づくりにも注力します。
プロダクトの立ち上げ時には、開発チームの一員として技術選定や運用課題の解決にも積極的に関与しています。 現在、各プロダクトはGoogle Cloudを中心に、AWSやAzureも併用しています。 インフラ構成の標準化や、共通のCI/CDパイプラインの提供にも取り組んでおり、プラットフォームチーム的な役割を多く担ってきました。
なお、弊社では11月に「顧客分析から専門性をなくす」というプロダクトコンセプトのもと EmotionTech CX/EX の新環境パブリックベータ版(以下、新プロダクト)を発表しました。 新プロダクトは2021年頃から構築が進められており、マイクロサービスの拡充を図りながら一部のお客様に試験的に利用していただき現在に至っています。
今年やってよかったこと
私たちSREチームの取り組みで今年「やってよかった」と感じたことを3点紹介します。
- 開発者にとってのインフラ設計・構築のハードルを下げる活動
- 非機能面の検証に活用可能な専用環境の提供
- 障害対応の準備と手順整備
開発メンバーにとってのインフラ設計・構築のハードルを下げる活動
2024年初頭時点で、プロダクトのインフラ(AWS、Google Cloud、Azure)はTerraformで管理していました。 当初は主にSREがTerraform Moduleの開発と構築を担当していましたが、次第に開発チーム全体でインフラコードを扱いやすくするための環境整備を進めました。 その背景には以下の要素があります。
- 2024年初頭時点で概ねインフラ構成のパターンやTerraform Moduleが揃ってきたこと
- 開発メンバーからも「インフラ設計・構築をやってみたい」という声が上がったこと
実施した具体的な取り組み
1. AWS Identity Centerの導入で権限管理を効率化
AWSでは商用環境、非商用環境を含めマルチアカウント構成となっております。 メンバーの増加に伴い権限管理やアカウント切り替え作業が複雑になってきたのでIdentity Centerを導入しました。 Identity Centerを導入することで、AWSアカウントを画面から簡単に切り替えられるようになったり、各自の役割と対象AWSアカウントに応じて柔軟に権限を付与できるようになりました。 (なお、Google Cloud、Azureについては特に課題を感じていなかったのでここでは述べません。)
2. GitHub ActionsによるTerraform planの自動化
Terraformの実行環境をローカルに依存しないよう、GitHub Actionsでplanを自動実行できる仕組みを整備しました。具体的には以下を実施しています。
- 各クラウドのTerraform実行用IAMとのOIDC認証
- コードの変更があったディレクトリで自動的にplanを実行・matrix strategyで並列実行
- 参照モジュールに変更がある場合も、モジュールを呼び出している各環境ディレクトリで自動planを行い、意図しないplan差分を検出可能にする
複数のパブリッククラウドを利用していることからローカルでTerraformを実行可能にするまでのセットアップ作業が煩雑でした。 この取り組みによりTerraformのPRを書いてもらうハードルが下がったと考えています。 現状、開発メンバーには以下のようなPRを作成してもらっています。
- 新規機能追加時のインフラ構築に伴うPR
- Cloud Monitoringのアラート定義に関するPR
これらの取り組みにより、開発メンバーがインフラコードにも関与しやすくなりインフラの更新を分担できるようになったと考えます。 今後もTerraform Moduleの改善など開発者体験を良くする取り組みはしていきたいと考えます。
非機能面の検証に活用可能な専用環境の提供
弊社ではgit-flowを採用しており、developブランチやreleaseブランチに対応する動作確認環境(以下、動作確認環境)を運用しています。 それとは別に性能検証や脆弱性検査等を利用目的とした専用環境(以下、専用環境)を新設しました。
専用環境は以下を含んでいます。
- 動作確認環境と同等構成のインフラ。動作確認環境とはGoogle Cloud Project/AWSアカウントレベルで分離
- 動作確認環境のRDBやBigQuery上のデータを専用環境に移行するツール
- 全てのフロントエンド、バックエンドマイクロサービスを一括でデプロイするツール
- 性能検証で利用するk6を動かすためのサーバー
- k6コードをデプロイするためのGitHub Actions (開発メンバーと共同で作成)
- ガイドライン(禁止行為、SREによるレビューが必要な事項、自由に行ってOKな行為を明文化)
- 利用者がいないときにコストカットするためリソースの起動停止を行うツール
専用環境の主な活用例は以下の通りです。
動作確認環境と分離することで、アプリケーションの機能試験に影響を与えずに自由に検証を行えるようになりました。 メンバーが性能検証や脆弱性検査といった活動に取り組みやすくなったのではないかと考えます。
障害対応の準備と手順整備
起こり得る障害を想定するため以下のような様式を用意しました。
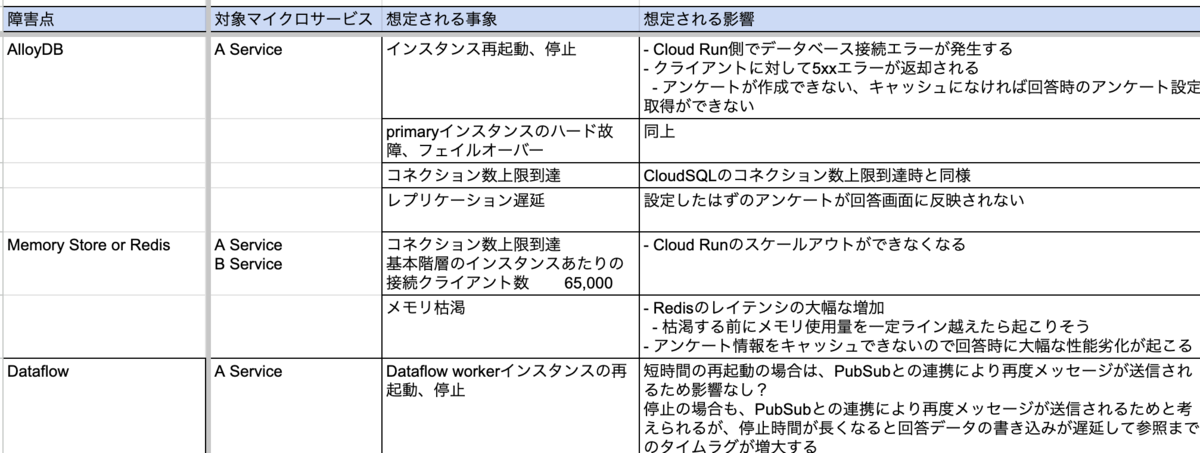
こちらはインフラ製品ごとに想定される事象と影響、再現方法を記載できるようにしています。 合わせてアプリケーション目線から書き出せる表も用意しています。
2023年以前はSREが事前に情報を推測して埋めていましたが、一部のマイクロサービスチームにもディスカッションを通じて追加情報を記入してもらいました。 さらに、発生確率が高そうな障害については、チームメンバーに対応手順書を作成してもらいました。 備えあれば憂いなしですね。 こちらは各マイクロサービスチームに少しずつ広めて継続的にブラッシュアップしたいと考えています。
今年SREチームがあまり手をかけなかったこと・今後の展望
Observablity製品への対応
弊社では数年前からNew Relicを導入しており、新プロダクトにおけるObservability対応も開発チームが主体となって進めてくれました。 特に、マイクロサービスにおけるRust OpenTelemetry対応やフロントエンド側の対応も 開発チームがしっかりと取り組んでくれたため、SREとしてはお任せ状態でした。 また、メトリクスダッシュボードについてもいつの間にか皆が必要と考えるものを用意してくれていました。心強いです。
SREとしては、異常にすぐ気がつけるよう、サービスやプロダクト横断で状況把握するための仕組みの整備を進めていければと考えています。
新しいマイクロサービスのインフラ構成を一から考えること
新プロダクト立ち上げの段階ではインフラ構成の型作りやCI/CDの設定はSREが実施していましたが、現状は開発メンバーがアップデートを行なってくれています。 私としては新規にインフラ製品を導入する際に非機能面から気になる点をレビューしたり、監視設計の方針をディスカッションしたりするくらいになっています。 開発メンバーには、新機能の開発だけでなくシステムのアップデートや運用についても自ら主導し改善に取り組んでくれる方が多く、励みになっています。 おかげさまで、SREはTopicScan®︎のような他プロダクトの立ち上げ支援やセキュリティ対策の現状整理といった活動にも時間を使うことができています。
ただ、どうしても機能開発が繁忙となって余力がない状況も出てくるとは思います。 そのような時に非機能面を中心に柔軟に支援を行うこともできればと考えます。 また、横断チームとしての立場を活かし、全体的な視野から偏りを発見しそのバランスを整える役割を担っていけると良いと考えています。
おわりに
いかがでしたでしょうか。 SREの役割は企業により大きく異なり、事業のフェーズによっても必要とされるタスクは多岐にわたると思います。 そのため、この記事では今年の活動を振り返りつつ、我々の業務内容を紹介させてもらいました。
個人的な考えとしては、現状は開発チームの中に入り込んだり、時には外から俯瞰してみたりと視点を柔軟に変えながら プロダクト全体をより良い方向に導くために行動することが重要だと考えています。 今後もチームの状況を見ながら、開発メンバーが価値を届けやすい環境を整えつつシステムの信頼性を制御する取り組みをしてきたいと考えます。
エモーションテックでは顧客体験、従業員体験の改善をサポートし、世の中の体験を変えるプロダクトを開発しています。ご興味のある方はぜひ採用ページからご応募をお願いいたします。